
What are Merkle Trees?
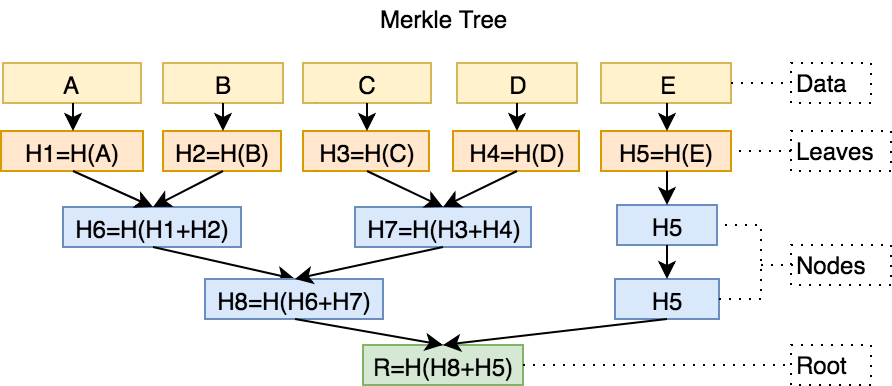
A Merkle tree is simply a tree of hashes, where the leaf nodes are a hash of the actual data block being stored, and each parent is a hash of of it’s children, which have been combined in some way (often as simple as concatenating the hash values of the chidlren and then then hashing that value). Merkle trees are most commonly implemented as binary trees, but there is nothing stopping you from implementing a Merkle tree as a ternary tree or irregular tree.
Merkle trees are used for efficient data verification, especially in distributed systems where data conistency is important. Without having to send the data itself, or even hashes of all the data, only the root hash needs to be sent, and if a discrepancy is found, the children are then sent to find which child contains the discrepancy. This process continues until the offending leaf node is found. The inconsistent leaf node can be found in O(log(n)) time. Because of this, the number of messages sent over a network and the size of the messages can be greatly reduced.
Verification Algorithm
1. Node A sends a hash of the file to Node B.
2. Node B checks that hash against the root of the Merkle tree.
3. If there is no difference, we are conistent. Otherwise, continue.
4. Node B will request the roots of the subtrees of that hash if it does not have them itself.
5. Node A creates the necessary hashes and sends them back to Node B.
6. Repeat steps 4 and 5 until you've found the data blocks(s) that are inconsistent.
It’s possible to find more than one data block that is inconsistent.
Common Use Cases
Although the concept of Merkle trees was aptented in the late 70’s, If you’re already familiar with Merkle trees, there’s a good chance that is because it is one of the main data structures underlying the blockchain. the distritbuted ledger component of cryptocurrencies like Bitcoin. However, Merkle trees are also used in other distributed peer-to-peer networks like Git and BitTorrent, distributed NoSL databases and copy-on-write filesystems like btrfs and ZFS. Personally, what really prompted me to make this post was my study of the OpenStack Swift Synchronization Bottleneck Problem. (Post on this subject coming soon). Swift is OpenStack’s object store. Merkle trees are useful in synchronizing data across a distributed object store because it allows each node to quickly identify records that have changed, without having to send all the data to make the comparison. Once a particular leaf in the tree is identified as inconsistent, only the record that is associated with that specific leaf is sent over the network.
Summary
– A trusted authority does not need to maintain the entire datastore, it only needs to maintain the root hash so other nodes can verify the integirty of the data
– Decouples the verification of the data from the data itself. The Merkle tree need not reside with data. The Merkle tree itself can also be distributed.
– Significantly reduces the message count and message size needed to verify data integrity. This means that the large number packets sent and received to perform data verification and synchronization can be greatly reduced, lowering network traffic.
Thanks for Reading! --- @avcourt
Questions? Join my Discord server => discord.gg/5PfXqqr
Follow me on Twitter! => @avcourt